Es gibt drei Arten Sprachmodelle (LLM’s) für eigene Anwendungen zu nutzen.
- Prompt Engineering
- Retrieval Augmented Generation
- Kombination von Sprachmodellen mit eigenen Daten
- Fine-Tuning
- LLM werden mit eigenen Daten neu trainiert
Wie funktioniert RAG?
Die folgende Abbildung zeigt eine RAG Pipeline:
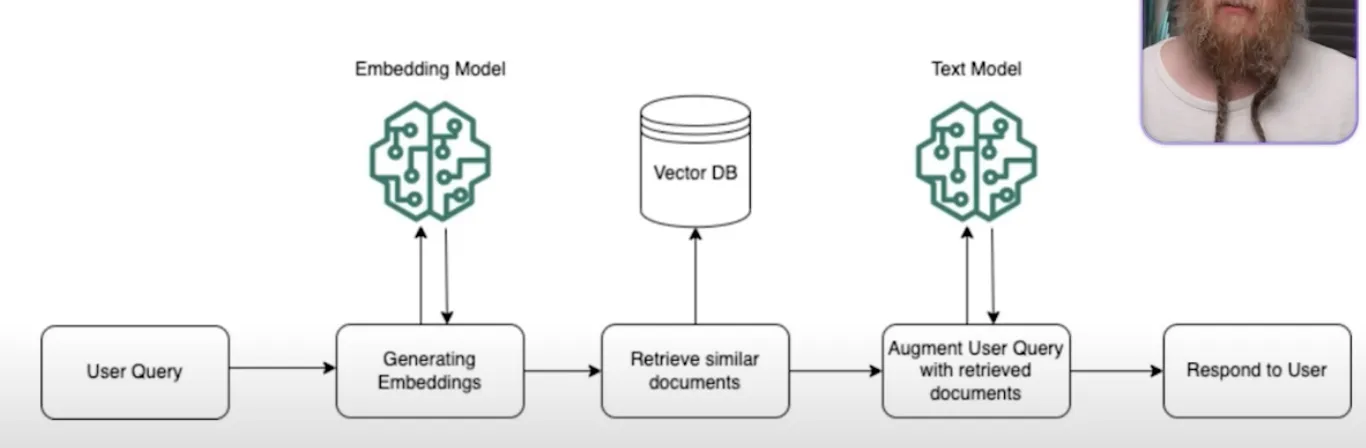
- Indexing stage
- Umwandlung privater Daten in durchsuchbare Vektorindex
- Verarbeitung verschiedener Datentypen wie Textdokumente, Datenbankeinträge und Wissensgraphen
- Storing
- normalerweise werden indizierte Daten im Arbeitsspeicher gespeichert
- gibt auch die Möglichkeit, diese in einem Verzeichnis zu speichern
- Vector Stores
- Vektorspeicher sind nützlich für die Speicherung der Einbettungen, die während des Indizierungsprozesses erstellt werden
- Embeddings
- Vectore Store Index konvertiert gesamten Text in Einbettungen mithilfe eines LLM
- Ausgabe der k ähnlichsten Einbettungen in Form von Textabschnitten
- Query
- ursprüngliche Abfrage und relevante Informationsabschnitte aus dem Vektorindex werden an das Sprachmodell weitergeleitet
- Retrieval
- Das System ruft die relevantesten Informationen aus gespeicherten Indizes ab und leitet sie an das LLM weiter, das mit aktuellen und kontextbezogenen Informationen antwortet.
- Postprocessing
- Response synthesis
- Die Antwortsynthese ist die letzte Phase, in der die Anfrage, die relevantesten Daten und die anfängliche Aufforderung kombiniert und an den LLM gesendet werden, um eine Antwort zu erzeugen.
Anwendungsbeispiel Suche nach passender Leuchte
from llama_index.core import VectorStoreIndex, get_response_synthesizer, Settings, Document
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.postprocessor import SimilarityPostprocessor
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.ollama import Ollama
import os
documents = [
Document(text='name": "Leuchte 1", "typ": "Pendelleuchte", "leistung": "12W LED'),
Document(text='name": "Leuchte 2", "typ": "Wandlampe", "leistung": "8W LED'),
Document(text='name": "Leuchte 3", "typ": "Stehlampe", "leistung": "15W LED"}'),
Document(text='name": "Leuchte 4", "typ": "Deckenleuchte", "leistung": "20W LED"}'),
Document(text='name": "Leuchte 5", "typ": "Tischlampe", "leistung": "10W LED"}'),
Document(text='name": "Leuchte 6", "typ": "Strahler", "leistung": "30W Halogen"}'),
Document(text='name": "Powerglare", "typ": "Flutlicht", "leistung": "100W LED"}'),
Document(text='name": "Leuchte 8", "typ": "Außenlampe", "leistung": "18W LED"}'),
Document(text='name": "Leuchte 9", "typ": "Notbeleuchtung", "leistung": "5W LED"}'),
Document(text='name": "Leuchte 10", "typ": "Schienenstrahler", "leistung": "25W LED"}'),
]
# Model Loading
os.environ["HF_HOME"] = "./model_cache"
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-base-en-v1.5")
Settings.llm = Ollama(model="llama3.1:8b", request_timeout=360.0)
# build index
index = VectorStoreIndex.from_documents(documents)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=10,
)
# configure response synthesizer
response_synthesizer = get_response_synthesizer(response_mode="compact")
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.2)],
)
# Query
response = query_engine.query("What is the name of our only Flutlicht type lamp")
print(response)
Learnings
- Funktionsweise RAG-Pipline
- Optimierung der Suchgeschwindigkeit mit dem Einsatz von Caching, Konfiguration des Synthesizer und “kleiner” Modelle (siehe Link zum Repo)
- Konfiguration der Suchmenge, Einflussfaktoren auf Suchergebnis